Month: November 2019
Grammatik over det Danske Sprog
Grammatik over det Danske Sprog (GDS) is a three-volume book series attempting to describe the grammar of the Danish language. The first edition was published in 2011, while the second is from 2019. Here is a few notes about the work:
- It is unclear to me if there is any difference between the first and second editions. I found no changes in the pages. I suppose minor changes might have occurred here and there.
- If one had thought that it would be straightforward to develop a computer-based grammar checker from the work, then one is wrong. It seems that the book has not been written with any computational linguistics in mind. But I should think that the many examples in the book can be used to generate data for training and evaluation computer-based systems.
- Interestingly, certain location adverbs are regarded as adverbs with inflection (page 216). Words such as ned, nedad and nede, I would regard them as independent lexemes, while GDS regards them as inflected based on telicity and dynamics/statics. In Wikidata, I have created three lexemes, rather than one lexemes with three forms. To me nedad is a compound of the two word “ned” and “ad”.
- Word stems are regarded as a feature of the form rather than the lexeme (page 165), so that the stem of adjective smukke is not smuk, but smukk!
- A word such as begynde is regarded as a cranberry word with gynde as the cranberry morpheme (page 255). Den Store Danske points to the middle German beginnen instead. If we take GDS’s approach then begynde should be said to be composed of the be- prefix and the gynde cranberry morpheme.
- From GDS and other Danish grammar works, I have not yet come to a clear understanding why certain linguistic elements are regarded as prefixes and when they are regarded as words in compounding. For instance, an- in ankomme is regarded as a prefix in GDS (page 256), but an is also an independent word and can go together with komme (“komme an”).
- The concept of “nexual” and “innexual” nouns (Danish: “neksuale/inneksuale substantiver”) is described, but it is not clear to me how words for agents (painter, human, animal) or words such as home or landscape should be annotated with respect to the concept.
- Lexemes for cardinal and ordinal numbers are called “kardinaltal” and “ordinaltal”. In Wikidata, I invented the words kardinaltalord and ordinaltalord to distinguish between cardinal numbers and the words that represent cardinal numbers.
- There are hardly any inline references. In many cases I am uncertain on whether the claim they present are widely established knowledge among linguistist or whether it is the authors’ sole expert opinion, which may or may not be contested.
Roberta’s +5-fine workshop on natural language processing
Interacting Minds Centre (Scholia) at Aarhus University (Scholia) held a finely organized workshop, NLP workshop @IMC, Fall 2019, in November 2019 where I gave a talk title Detecting the odd-one-out among Danish words and phrases with word embeddings.
Fritz Günther (Scholia) keynoted from his publication Vector-Space Models of Semantic Representation From a Cognitive Perspective: A Discussion of Common Misconceptions (Scholia). A question is whether the distributed semantic models/vector models we identify from computing on large corpora makes sense with respect to cognitive theories: “Although DSMs might be valuable for engineering word meanings, this does not automatically qualify them as plausible psychological models”.
Two Årups displayed their work on SENTIDA “a new tool for sentiment analysis in Danish”. In its current form it is an R package. It has been described in the article SENTIDA: A New Tool for Sentiment Analysis in Danish (Scholia). According to their evaluation, SENTIDA beats my AFINN tool for Danish sentiment analysis.
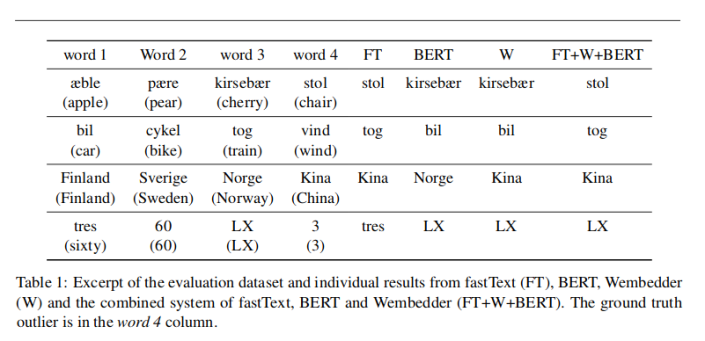
My own talk on Detecting the odd-one-out among Danish words and phrases with word embeddings was based on the distributional semantics representation evaluation work together with Lars Kai Hansen (Scholia): Our 2017 paper Open semantic analysis: The case of word level semantics in Danish (Scholia) and our newer 2019 paper Combining embedding methods for a word intrusion task (Scholia). The idea is to look on a Danish textual odd-one-odd task/word intrusion task and see what models trained on various corpora can do. Our current state-of-the-art is a combination of embedding models with fastText as the primary one and using Wembedder for proper nouns.
Two Aarhus students, Jan Kostkan and Malte Lau Petersen (Scholia) are downloading European parliament text data and analyzing them. A text corpora from Folketinget, the Danish Parliament may be available with 10s of millions of sentences.
Ulf Berthelsen, whom I share the Teaching platform for developing and automatically tracking early stage literacy skill (Scholia) research project with, spoke on late state literary skill.
Natalie Schluter (Scholia) spoke on glass ceiling effects in the natural language processing field. She has an associated paper The glass ceiling in NLP (Scholia) from EMNLP 2018.
Matthew Wilkens (Scholia) spoke on “Geography and gender in 20.000 British novels”, – large-scale analysis of how geography was used in British novels. This part fell much in alignment with some work I did a few years ago with geographically mapping narrative locations of Danish literature with the Littar website. and the paper Literature, Geolocation and Wikidata (Scholia) from the Wiki Workshop 2016.
There was a number of other contributions in the workshop.
The second day of the workshop featured hands-on text analysis with among others Rebekah Baglini and Matthew Wilkens getting participants to work on prepared Google Colab notebooks.
HACK4DK 2019: Lydmaleri
I HACK4DK, en årligt tilbagevendende begivenhed i efterårets København, bringer museer, biblioteker, arkiver og hvad der nu ellers er deres åben data så entusiaster i form af programmører, data scientists, designere og lignende kan bygge ting og sager, typisk et computerprogram med en visualisering.
Jeg har vist været med fra 2013. I alle fald har min blog de billedremix jeg lavede: Gammelstrand remixed og Jailhouse remixed, – senere Kulturvet remixed og Fishy fishmongers of Fischer. Nyere HACK4DK bidrag er at finde på https://fnielsen.github.io/. Sidste år blev det til en analyse af danske film med data fra Det Danske Filminstitut via de data som hovedsagligt Steen Thomassen har overført til Wikidata.
HACK4DK 2019 spandt af på SMK på blot halvanden dag, fredag, lørdag, 15.-16. november 2019. Resultatet blev en ganske god række af projekter og visualiseringer. Mens det de tidligere år har været op og ned med folk der har været i stand til at få noget nyttigt ud af deep learning, så var der flere projekter der kom ganske godt i land med denne teknik.
Et projekt kombinerede styleGANs, deoldify og GPT-2 tekst-generering på gamle foto fra Kolding, – et klassisk datasæt i HACK4DK-sammenhænge. En flig af resultatet er vist i et af Andreas Refsgaards tweets. Her bliver der tilsyneladende samplet i et latent underrum og farvelagt via deoldify. Hvad måske var mest interessant var de falske biografier der kunne skabes via den tilhørerende tekst til billederne og GPT-2 samt en smule hjælp i form af begyndelser af tekst. Runway ML var anvendt.
Flere benyttede så vidt jeg forstod prætrænede Javascript-version af style-transfer-netværk, så som arbitrary-image-stylization-tfjs.
Albin Larsson konstruerede en interaktiv visualisering for SMK-malerier, så vidt jeg forstår baseret på Christopher Pietschs VIKUS viewer.
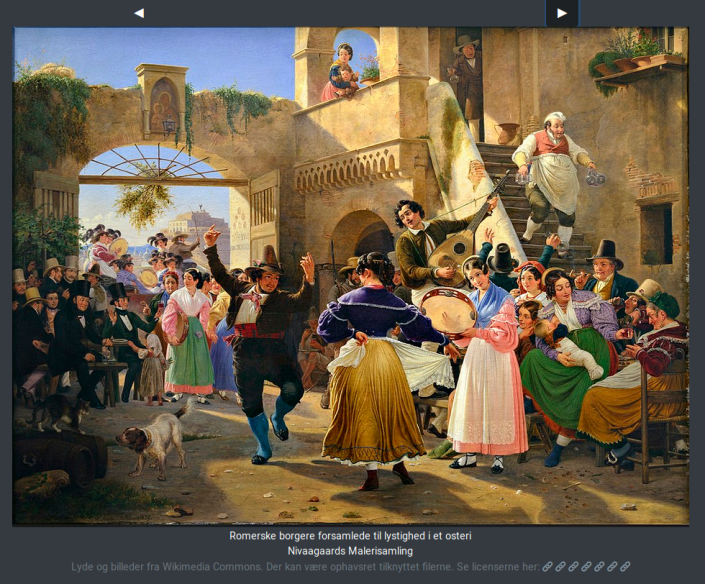
Jeg benyttede malerier og maleridata fra danske samlinger sådan som de er repræsenteret i Wikidata og Wikimedia Commons til Lydmaleri, hvor web-brugeren bliver præsenteret for et maleri med områder bundet til relevante lyde. For eksempel, billedet Et selskab af danske kunstnere i Rom (SMK, Wikipedia, Wikimedia Commons, Wikidata) viser en hund i højre hjørne. Når brugere klikker på hunden i Lydmaleri lyder et vov. Det er også muligt for brugeren at klikke sig videre til andre billeder. Til at få fat i data anvender jeg en SPARQL-forespørgsel der sendes til Wikidata Query Service. Resultatet behandles i websidens Javascript der afspiller lyden når klikket falder i lyd-rektanglet og skifter billedet og lyde ud når der bladres videre.
Lydmaleri benytter ingen maskinlæring. Istedet er objekt-genkendelsen i billedet baseret på informationen der eksplicit er indtastet i Wikidata. For Et selskab af danske kunstnere i Rom er således specificeret at der afbildes en hund og med en såkaldt kvalifikator kan med procent-koordinater angives hvor i billedet hunden befinder sig. Til indtastningen af koordinaterne kan anvendes Lucas Werkmeisters wd-image-positions web-applikation. Dette er en ganske tidsrøvende proces, som jo dog kan gøres kollaborativt på Internettet.
Som frontenddeveloperwannabee kommer mine CSS- og Javascript-evner nogle gange til kort. Billede-loading kunne være hurtigere og positioneringen af billederne og klik-området kunne også forbedres. Der er udfordringer med visse systemer. Således vil Apples Safari-browser tilsyneladende ikke afspille lydene, vistnok fordi OGG-audio-formatet ikke understøttes. Min Ubuntu Firefox og Ubuntu Google Chrome har ikke sådanne problemer. Android-systemer kan have problemer med at vise visse af sidens komponenter sådan som jeg havde tænkt det.

{kind=link}