Month: June 2019
On the road to joint embedding with Wikidata lexemes?
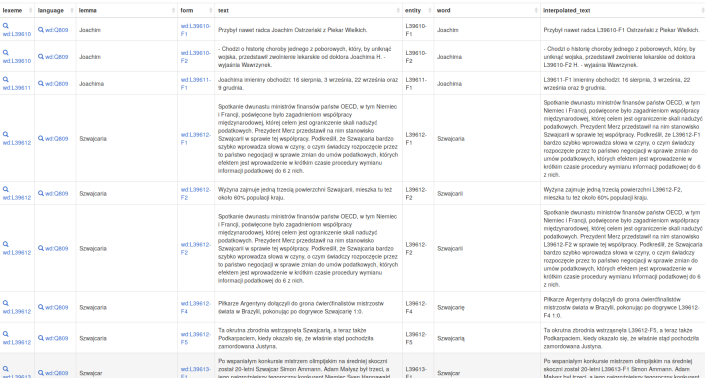
Is is possible to use Wikidata lexemes for joint embedding, i.e., combining word embedding and knowledge graph entity embedding?
You can create on-the-fly text examples for joint embedding with the Wikidata Query Service. This SPARQL will attempt to interpolate a knowledge graph entity identifier into a text using the short usage example text (P5831):
SELECT * {
?lexeme dct:language ?language ;
wikibase:lemma ?lemma ;
ontolex:lexicalForm ?form ;
p:P5831 [
ps:P5831 ?text ;
pq:P5830 ?form
] .
BIND(SUBSTR(STR(?form), 32) AS ?entity)
?form ontolex:representation ?word .
BIND(REPLACE(?text, STR(?word), ?entity) AS ?interpolated_text)
}
The result is here.
The interpolations are not perfect: There is a problem with capitalization in the beginning of a sentence, and short words may be interpolated into the middle of longer words (I am not able to get a regular expression with word separator “\b” working). Alternatively the SPARQL query result may be downloaded and the interpolation performed in a language that supports advanced regular expression patterns.
The number of annotated usage examples in Wikidata across languages is ridiculously small compared to the corpora typically applied in successful word embedding.
Update:
You can also interpolate the sense identifier: Here is the Wikidata Query Service result.
